Published:
Updated:
by Wayne Smith
Keywords and document retrieval, Old-School
There are 400,000,000 pages indexed by Google and Google is aware of maybe 2,000,000.000 URLs. There are less than 1,000,000 words in the English language. A typical vocabulary of words would be less than 40,000. A functional vocabulary of less than 10,000 words, and at 10,000 that would include mice and mouse two words same search intent, the same entity when we are talking about language processing.
User Query Intent + SEO insights into entities
A query for "how to make pizza," could be interpreted fairly as asking for a recipe. With the Natural Language Processing algorithm using entities: Pizza is an entity under the entity of food and related to food is the word recipe, which is closely related to the concept (entity) of "how to make." A search for "how to make pizza," pulls up "pizza recipes," even when the term "how to make," does not exist on the page.
To scale document retrieval for 5 digits or more. The document's words can be indexed and each table can point to the pages that contain the words. These two indexes are then merged and we have a working data set much smaller than the 400,000,000 pages which can then be searched for an exact match, etc, without taking a week to provide the results. Using entities instead of words is another magnitude of scale, and improves the document retrieval system ... the intent of somebody looking for the diet of a mouse is the same as the intent of somebody looking for the diet of mice.
What are Search Entities?
Entities are like keywords but with a lot of information added. Mice and mouse are the same search entity, (index file), and natural language processing has learned to use "a mouse" for one and "the mice" for many, (four words two entities). Expanding on the entity concept, or adding AI natural language processing related entities can be included as part of the record for an entity.
Google's Patent US20160371385A1
Methods, systems, and computer-readable media are provided for collective reconciliation. In some implementations, a query is received, wherein the query is associated at least in part with a type of entity. One or more search results are generated based at least in part on the query. Previously generated data is retrieved associated with at least one search result of one or more search results, the data comprising one or more entity references in at least one search result corresponding to the type of entity. One or more entity references are ranked, and an entity result is selected from the one or more entity references based at least in part on the ranking. An answer to the query is provided based at least in part on the entity result.
Search using natural language processing examines the topic of the query and websites. A knowledge graph can be built around what was a keyword, and related words and synonyms created. One might say a machine-readable ID is an enhanced keyword.
Using machine-readable topical IDs instead of keywords improves the quality of results. For example, old-school SEO would use the same keyword multiple times but books and natural language use related concepts aka topical clusters. Instead of repeating the name George Washington (Old-School) other facts about George Washington on the page ... like First President of the USA, Signer of the Declaration of Independence, Born Feb. 22nd 1732 ... reinforce the page is about George Washington without repeating his name.
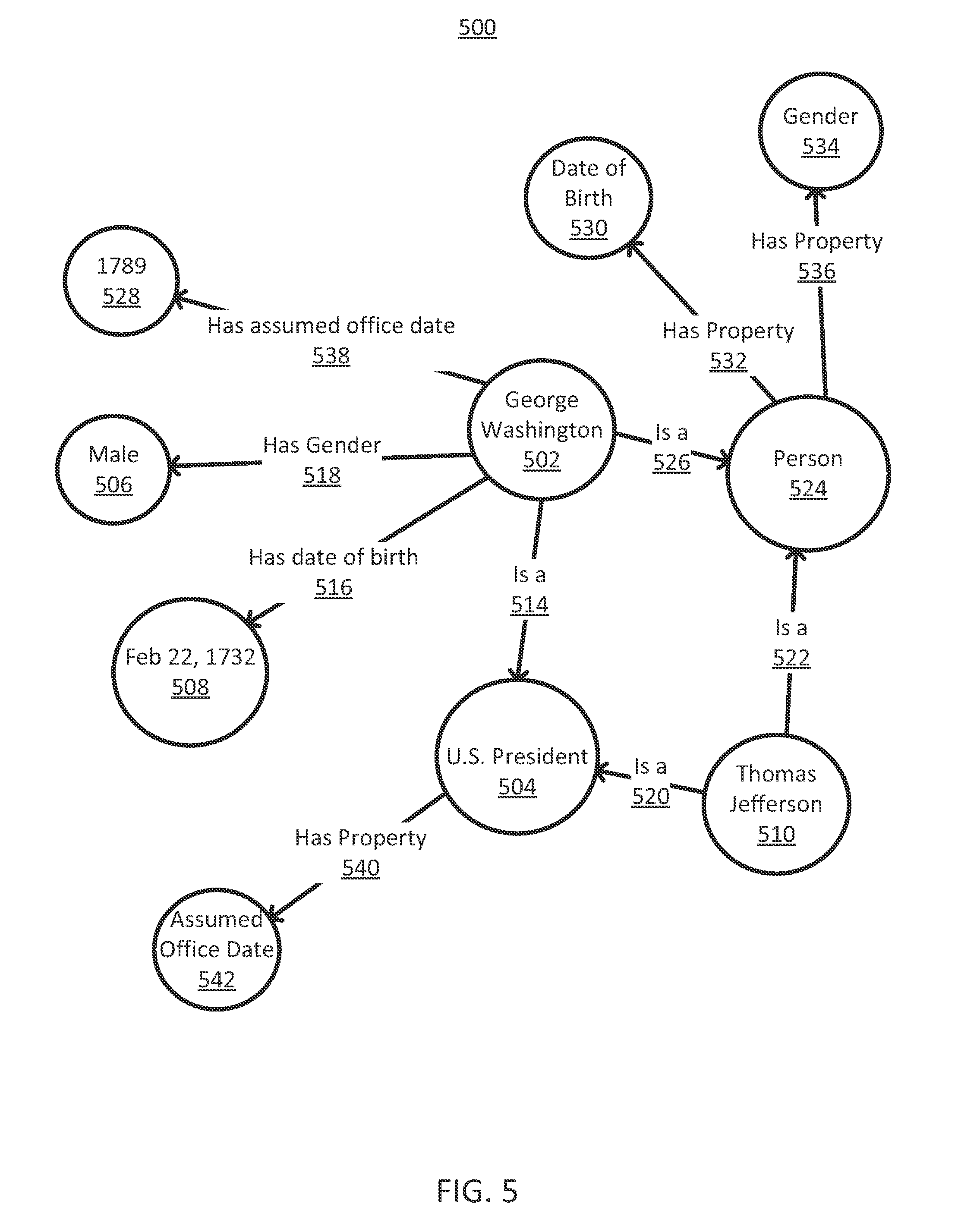
Additional benefits include the fact that all languages share a common machine-readable ID; Diet in French is régime, but it is the same concept or thing and has the same machine-readable ID https://www.google.com/search?kgmid=[entity]. Note KGMID or Knowledge Graph Machine ID is the same as the entity and when using the KGMID the search query is already known.
Search with natural language processing can make these associations and, (do not take this the wrong way), change the search to include the additional terms as related to creating an improved data set that matches the topic and the keywords. This smaller data set can be processed for an exact match with the query.
Entities can provide additional search engine enhancements. A search that includes the KGMID term "Covid" can have an advisory notice added, show a knowledge panel, and turn on YMYL, (Your Money Your Life), the algorithm for sorting the search results. YMYL essentially requires sites to have a high authority value. If you compare the EEAT values of a salesman with a quantity of knowledge about his products vs Einstein who only knows about one thing. Einstein has more Authority on the subject because his words have been cited more than the salesman.
Google Knowledge Graph and Search Entities
Google Knowledge Graph are search entities. Google purchased Freebase (database), from the startup Metaweb Technologies which began the process of creating a database of knowledge based on machine-readable IDs, and began building the relationships between concepts. Much of the data in the Google Knowledge graph is sourced from the Freebase database and retains the associated ID number used by Freebase.
The Knowledge Graph also creates machine-readable IDs from Wikipedia. They are also created by Google Trends for common searches. People and organizations can get a machine-readable ID and a knowledge graph entry, by being referenced on source sites. The Knowledge Graph also uses IMDb, (an online database of information related to films, television series, podcasts, home videos, and video games) to create machine Readable IDs for people, and things.
Schema SEO
Schema markup is not a requirement for the usage of search entities. Topics can appear as text the same as if the document were a book or other natural language document. But schema markup unambiguously provides information to a search engine that otherwise may be ambiguous. A web page may have a lot of data that is not specifically related to the topic. Webpages tend to have navigation links etc, which relate to the site but not the topic. Or, some documents may digress into other topics of interest to the reader. Schema can clarify what is relevant information reducing the amount of resources needed for ranking a page.
Topical Authority
Using search entities makes it possible to build topical authority. A site may have a page about Great Danes but it has many pages about dogs - the page about Great Danes is on a topic the site has Experiance-Expertise-Authority on.
Gain of Knowledge Algorithm
The gain of knowledge algo would be implemented using Google's patent S20050177561.
An improved method for retrieving documents from the web and other databases that uses a process of continuous improvement to converge toward near-perfect results for search queries. The method is very highly scalable, yet delivers very relevant search results.
In essence, Google can evaluate the results of the search and using topical machine IDs to determine if a different result than the one selected has more topical knowledge, or if the selected result has more knowledge than the listings above it ... The more knowledgeable page can then receive a benefit or improvement to their natural score. This is done post-search... it is observed to add volatility to the search results.
The Gain of Knowledge Algorithm is post Google's adoption of search entities, and there is no obvious way to implement the algorithm without machine-readable IDs.
An Exhibit from the recent testimony from Google.