Published:
Updated:
by Wayne Smith
A query for "how to make pizza," could be interpreted fairly as asking for a recipe. With the Natural Language Processing algorithm using entities: Pizza is an entity under the entity of food and related to food is the word recipe, which is closely related to the concept (entity) of "how to make." A search for "how to make pizza," pulls up "pizza recipes," even when the term "how to make," does not exist on the page.
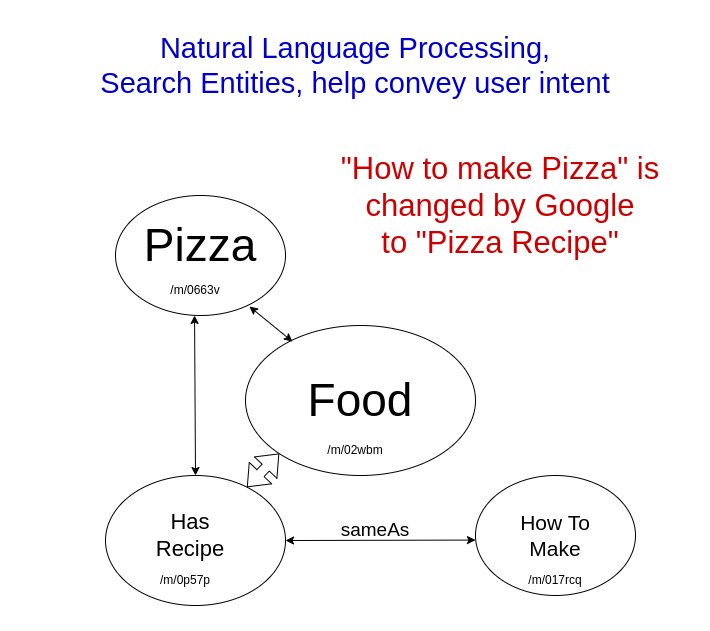
Interestingly, a search for "do it yourself pizza," also pulls up pizza recipes, and "do it yourself" does not appear on the recipe pages. Don't take this the wrong way but when you search for "do it yourself pizza" Google changes your search to include recipes. You can also search for "bread recipes" by searching for "do it yourself bread"
It is said there are three types of user intent: informational (how to, the recipe would be informational), transactional, and navigational, with an intent of commercial added that makes four types. OK, that may be true but it speaks very little to the implementation of SEO or Marketing, (Marketing needs micro-intent). Regardless of which intent from a psychological point of view -- if somebody enters "Beatles songs" into the search box are they looking for information about the band's songs; or do they want songs about bugs?
The Google Knowledge Panel reveals the entity via its kgmid number. Although entities exist that don't have Google Knowledge Panels, IE Sites are entities but not all sites have a Knowledge Panel.
For SEO considerations
Related terms need to exist on the page for Natural Language Processing to correctly classify the on-page content and extract the entities.
There is a ranking benefit provided for a gain of knowledge ... On-page content which only reaches the minimum of knowledge on an entity is less helpful to users than pages that present more knowledge; Knowledge is calculated by the presence of related entities. If a page is about a beatle song, mentioning the band members is better than a page about the same song that does not include them. There is no "the list" of the related entities, machine learning allows the natural language processing to learn about new related entities.
Old school SEO would try to add the keyword more times to the page; entity SEO is about adding more entities or knowledge about the subject in the same way books demonstrate knowledge on a subject by adding knowledge not repetition of the words in the title.
Long tail searches for user intent
Additional keywords words (long tail search) that convey the intent:
- Informational intention:
- Who, what, where, when, why and how.
- How to, (or how to make, how to cut, how to build), Recipe; Do it yourself, An example.
- What is, how to use, What does,
- Transactional intention: Supplier, Wholesaler, Distribitor, (name of product)
- Navigation intention keywords: Apple, Amazon chromebooks, BBB city name, Denny's menu, download, source code, github, reddit
And, additional user intentions:
- Commercial intention: Hours of, Address for,
- Local intent: Near me, Near by
For Digital Marketing
For digital marketing there are micro-intents. For commercial for example there are buyers and sellers. For Navigation, there are micro-intents based on demographics. For Transactions, there are micro-intents based on kinds of services. For Information, there are micro-intents for research, price and availability, nearby ... etc.
SEO and content intent + entity matching
For On-page SEO, instead of a reduction of concepts, as happens with user intent; entity SEO for content is about including related entities, and matching intent. Food is a type of thing that has nutritional value, serving portions, preservation, etc. Pizza is a type of food so it inherits all of the properties of food. A Recipe is a type of "how to," which has preparation time, steps, measurements, etc. Both food and recipe have a schema that gives a list of properties they may have. Entity SEO is about providing a gain of knowledge - and if the related concepts tie back to pizza the page is more about pizza than a page that only has the word pizza. Pizza has its gkmid and has selections of toppings, it can be al la carte or have other food available which is commonly served with pizza.
Using the schema.org recipe can be helpful in two ways. It organizes what needs to be on the page, and it explicitly in machine-readable format does the natural language processing. Schema does not itself affect page ranking, the same content without including schema will rank the same. However, recipes are displayed as an individual rich result or part of a host carousel. It is the content that does the magic, not the schema - except for any special display in search.
The "nutrition" property is not shown for the featured on Google but is shown on Schema.org for either a menu item or recipe.
A breakdown of entities related to pizza, at first inspection, would be:
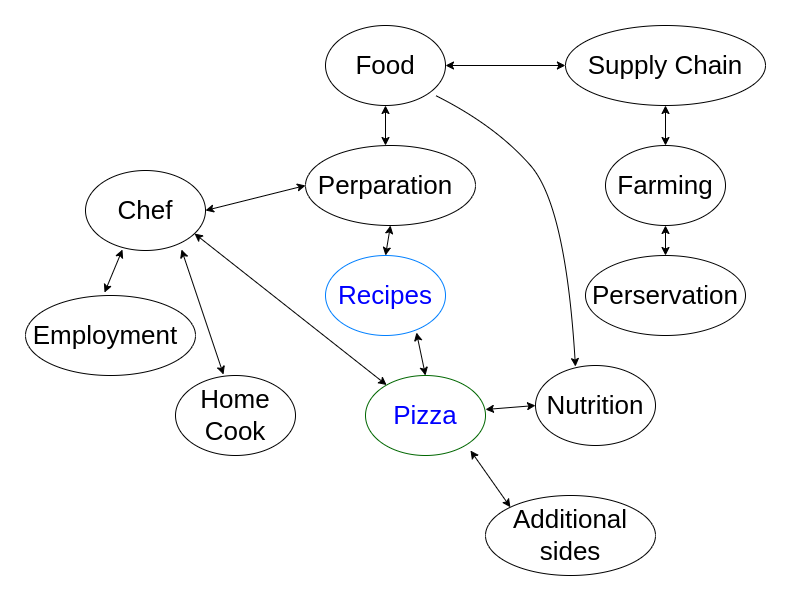
Preservation can be included by saying: The Pizza can be stored in the freezer before cooking for up to a week. Information about where to get ingredients speaks to the supply chain. Additional recipes on the side can speak to what other foods can be served with the pizza. It is also helpful if one can present the information from personal experience to not look like it is AI content. But these are mentions with a supporting role not to compete with the main topic, which is for pizza recipes, the user intent is information and instructions on how to make a pizza.
Experience, Expertise, Authority, and Trust - E-E-A-T algorithm
The E-E-A-T algorithm is site-wide or the website, and organization. It extends to other sites for the Author. If a @person schema or profile page exists for the chef, and the page has a byline, "Recipe by" the accumulated E-E-A-T value will apply to the page, and help to set the ranking of the page in the search. Depending of course on the ranking requirements to meet user intent.
Expertise can be shown by details on the profile page such as employed as a chef, and other pieces of information.
Experience is time and quantity.
Authority which can be to the page or site. Would be how many other people or sites are linking to the page, and how many people are commenting to give it a thumbs up?
The trust would be how somebody contacts the site for information. If products are being sold what is the return policy and how to contact them? There are many trust factors, but it is not necessary to have all of them.